
Today, searching for malware is pretty much a Big Data problem. Cybercriminals and Malware-as-a-service providers have been using cloud infrastructure to disseminate their malicious files. As cloud providers want to get more customers at any cost, they have been offering free trials and premium accounts. Also the process of creating new accounts have been facilitated — some cloud providers just require a valid email account — so, of course, the process of creating new accounts can be automated (Below, a video from Black Hat Conference in 2014, which shows how new cloud service accounts can be automated)
Added with the fact that malicious traffic through the Internet is blended with the regular cloud traffic — therefore, bypassing IDSs — all that caught the cybercrimianals eyes: at the present time, more than half of malware on the Internet is hosted on Cloud Providers.
When we talk about Cloud Computing, it comes to mind Big Data. In this case, it also happens with malware distribution in Cloud Services too. Daily, Gigabytes/Terabytes of malicious files have been moving from a client/Cloud to another by Cybercriminals. Therefore, the volume of data to be analyzed is huge — so, we have a Big Data problem. In order to solve it, it is reasonable to use Big Data tools like Hadoop.
If you are not familiar with Hadoop, it basically implements the MapReduce algorithm, which is an implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster. Maybe you won’t understand some concepts and codes in the next paragraphs on this post. There are many good books and tutorials about it on the Internet, I suggest you google it!
In this post, we’ll modify some classes on Hadoop to read a file per map. After that, we’ll implement a MapReduce application to find packed (upx) files.
First, I will write about how to implement one file per map on Hadoop (2.x versions). I came across with this problem when I was trying to analyze an (huge?) executable (malicious) file database (about 200GB). The code showed is based on the Hadoop, The Definitive Guide (4th Editon) book, written by Tom White.
It’s known Hadoop’s default implementation for the inputs is to split files, which each chunk is sent to a Mapper (node). Moreover, each record is a (entire) line from the file. However, in certain situations, this doesn’t work. Particularly, I was interested in each Mapper has as its input an entire file (instead of a piece of it) because each file should be submitted to a filter that was located in the Mappers. Therefore, each Mapper should be able to “visualize” the entire file during the mapper phase.
For better understanding, the image below shows the sequence used on Hadoop framework for all stages. For simplicity, the three classes, which come before the Mapper circle (InputFormat, InputSplit, and RecordReader) are ones we have to modify (override its methods). According to the official documentation, Map-Reduce framework relies on the InputFormat of the job to:
“
- Validate the input-specification of the job.
- Split-up the input file(s) into logical InputSplits, each of which is then assigned to an individual Mapper.
- Provide the RecordReader implementation to be used to glean input records from the logical InputSplit for processing by the Mapper.
”
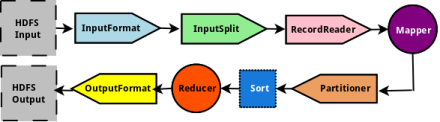 Source: http://www.polarsparc.com/xhtml/Hadoop-6.html
Source: http://www.polarsparc.com/xhtml/Hadoop-6.html
The default behavior of the InputFormat class is to split the input into logical InputSplit based on the total size, in bytes, of the input files. However, the FileSystem (eg., HDFS) blocksize of the input files is treated as an upper bound for input splits. A lower bound on the split size can be set via mapreduce.input.fileinputformat.split.minsize.
What we will do here is to extend the InputFile class to ReadEntireFileInputFormat class. Basically, it’ll tell that we don’t want to split the files — through the method isSplitable() — as well as it’ll return a extended RecordReader object, which is going to be our new record (whole file instead of a line from it). Note that we should write the new record class (extended from RecordReader class) as well. Both classes are listed below. ReadEntireFileInputFormat and ReadEntireFileRecordReader extends InputFormat and RecordReader respectively. Pay attention to the comments, I tried to explain each method step-by-step.
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class ReadEntireFileInputFormat extends FileInputFormat<Text, BytesWritable> {
/*This method tells to InputSplit class if the file should be splited or not.
/*In this case, it won't.
*/
@Override
protected boolean isSplitable(JobContext job, Path file) {
//returns false so that InputSplit does not split the file
return false;
}
/*This method creates a record object, initializes it and returns to the
/*mapper
*/
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//Note that ReadEntireFileRecordReader is our new record class, which
//we should write as well.
ReadEntireFileRecordReader reader = new ReadEntireFileRecordReader();
reader.initialize(split, context);
return reader;
}
}
Listing – ReadEntireFileInputFormat class
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.commons.codec.digest.*;
public class ReadEntireFileRecordReader extends RecordReader<Text, BytesWritable> {
private Configuration conf;
private FileSplit fileSplit;
private byte[] value;
private boolean isProcessed = false;
/*This method just gets the InputSplit (each file split) object and stores it /*in an internal variable to be handled by the other methods
*/
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.conf = context.getConfiguration();
//split will be our entire file here because
//we set isSplitable() as false on ReadEntireFileInputFormat class
this.fileSplit = (FileSplit)split;
}
/*This is the most import method of the class. Based on the FileSplit object, /*it opens the file in HDFS and creates the value (entire file content). In th /*is case, the value is the whole binary content of the file.
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
//DO NOT process if we already processed this split (=whole file)
if(!isProcessed) {
byte[] rawContent = new byte[(int) fileSplit.getLength()];
Path filePath = fileSplit.getPath();
FileSystem fs = fileSplit.getFileSystem(conf);
//FSDataInputStream is provided by hadoop package so that we can
//read from HDFS
FSDataInputStream in = null;
try{
in = fs.open(filePath);
//put the content of file (in) into
//the byte array (rawContent)
IOUtils.readFully(in, rawContent, 0, rawContent.length);
value = rawContent;
}
finally{
IOUtils.closeStream(in);
}
isProcessed = true;
return true;
}
/*if the split already was processed, we return false cause we
/*don't want to process the same split twice.
*/
return false;
}
@Override
/*This method is very import, it defines what will be the key for the record.
/*In this post, I just defined the hash of file as key.
*/
public Text getCurrentKey() throws IOException, InterruptedException{
//return the name of file as key
//'Text' is the (seriable) String type for Hadoop
String md5 = DigestUtils.md5Hex(value);
return new Text(md5);
//if you wanna return the name file as key
//return new Text(this.fileSplit.getPath().getName());
}
/*This method returns the value content, which, in our case, is the content of /*the file. Note that because our content is a 'binary' content, we are return /*ing a BytesWritable object
*/
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException{
return new BytesWritable(value);
}
/*This method returns the state of record processing. For simplicity, let's
/*return 0 if the file is not processed or 1 otherwise.
*/
@Override
public float getProgress() throws IOException {
return isProcessed ? 0 : 1;
}
/*As we should write all methods for the class, we also should write this.
/*However, as we don't have nothing to do here, we'll just do nothing.
*/
@Override
public void close() throws IOException {
//do nothing but it is called each time a split is created!
}
}
Listing – ReadEntireFileRecordReader code
That’s all you have to do in order to Hadoop reads one file per map. Now, we have to write the Mapper and Reducer to find UPX packed files. There are many ways to discover if a file is packed with UPX packer. Let’s do that using the easiest way. Before, I opened a packed file, as follows:

There are 5 files in my directory. I opened (hex view) mf.exe, which is a upx packed file:

Typically, UPX packer writes two strings, UPX0 and UPX1 in the file. The image shows the respective hex numbers, which are linked through a arrow. For simplicity, we aren’t interested in which PE section these string are :)), In our code, we’ll store the hex content of the file and then search for these two strings.
The Mapper, listed below, gets the hex string content of the file and then compares it with the two strings: The output is the key (file hash) and a string (Text type ) saying if the file is or not a upx packed file.
package readbinary;
import java.io.IOException;
import org.apache.commons.codec.binary.Hex;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ReadBinaryMapper extends Mapper<Text, BytesWritable, Text, Text> {
String myHex;
public void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
myHex = Hex.encodeHexString(value.getBytes());
myHex = myHex.substring(0, value.getLength());
//UPX0 and UPX1
if(myHex.contains("55505830") && myHex.contains("55505831")) {
context.write(key, new Text("is UPX"));
}
else context.write(key, new Text("is not UPX"));
}
}
The Reducer, just forwards its input to the output:
package readbinary;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReadBinaryReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for(Text val: values) {
context.write(key, val);
}
}
}
And finally, the Driver Code:
package readbinary;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReadBinary {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Read Binary");
if(args.length != 2) {
System.err.println("Usage: ReadBinary <input dir> <output dir>");
System.exit(-1);
}
job.setJarByClass(ReadBinary.class);
job.setMapperClass(ReadBinaryMapper.class);
//job.setNumReduceTasks(0);
job.setInputFormatClass(EntireFileInputFormat.class);
job.setReducerClass(ReadBinaryReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
The code part, now jut compile your code, generating the .jar file and run Hadoop. You should be able to get the entire file per map and evaluate if it is or not a upx packed file. As key, the value is the hash file string, as listed below:


I hope this post motivates you as the point of start in your projects involving malware and Cloud Computing. I’d like to point out here, the solution presented here is not perfect in a performance view. If your files are not large enough (has the block HDFS block size ~128MB) you’ll have the small file problem. There are many ways you could solve it (eg., using .har files). If you still have problems after reading this post or even if you are not familiar with Hadoop, please, write to emanuelvalente at gmail.com. I will be more than pleased to help you! :))

 Source: http://www.las.ic.unicamp.br/ paulo/teses/20121128-PhD-Andre.Ricardo.Abed.Gregio-Malware. behavior.pdf
Source: http://www.las.ic.unicamp.br/ paulo/teses/20121128-PhD-Andre.Ricardo.Abed.Gregio-Malware. behavior.pdf

 File program output after renaming a jpg file
File program output after renaming a jpg file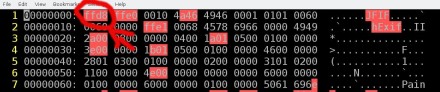 First bytes of a jpg file – JPG’s magic numbers are red rounded.
First bytes of a jpg file – JPG’s magic numbers are red rounded. Last bytes of a jpg file – JPG’s magic numbers* are red rounded. – *Note that some jpg files end with ff d9 or ff d9 0a
Last bytes of a jpg file – JPG’s magic numbers* are red rounded. – *Note that some jpg files end with ff d9 or ff d9 0a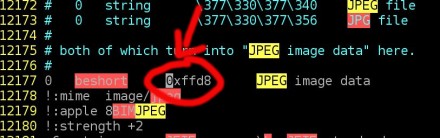 /usr/share/misc/magic – change 0xffd8 to 0x00d8
/usr/share/misc/magic – change 0xffd8 to 0x00d8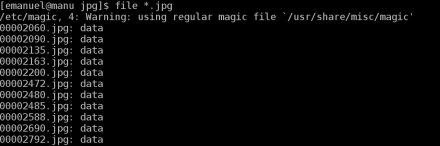 file program output after changing /usr/share/misc/magic file
file program output after changing /usr/share/misc/magic file